If your day-to-day involves workflows with long-running tasks, I have good news for you: we just released a new checkpointing feature that makes it possible to save intermediate outputs for a task and resume work from that point if the task gets interrupted.
For context, the Cromwell workflow engine we use in Terra already had a smart resume capability at the level of the workflow, called “call caching“. Briefly, the idea is that if your workflow fails or is otherwise interrupted partway through execution, you can resume the workflow from the point of the failed task without re-running tasks that completed successfully before the failure. However, you still have to re-run the failed task itself from scratch.
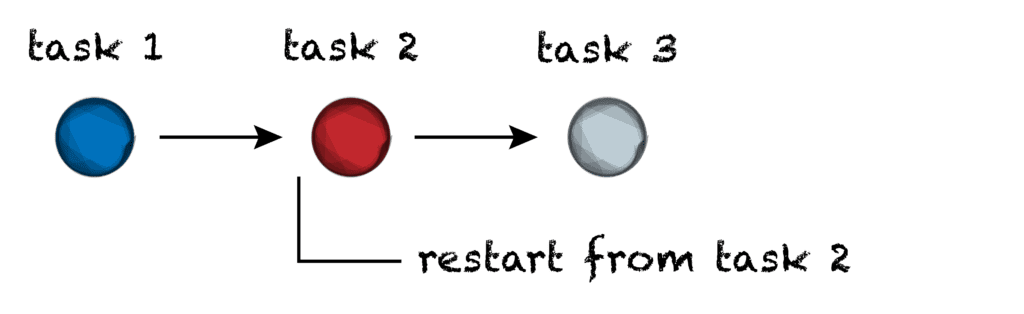
If the task failed because of a problem with the data or the software, you probably need to do something to fix the problem anyway, so there’s no way around that. But if it was interrupted by a transient error or by preemption, checkpointing can make a big difference.
Preemptible VMs save you money
“Preemption” is when the virtual machine (VM) that is running that task for you is taken away and given to someone else. Rude as that may sound, this is actually an opt-in feature; you can choose to rent “preemptible” VMs at a fraction of the normal price, with the understanding that during if someone else needs the VM while your job is running, the system will take it away from you mid-run and give it to them.
Preemptible VMs are very attractive for controlling costs, and in our experience, they are well worth the risk for short-running tasks or if you can afford to wait a bit longer for your results. For long-running tasks however, the tradeoff is not as appealing since any preemption can delay your final results significantly. While Cromwell will restart a preempted task for you automatically, it does have to restart that specific computation step from scratch.
Checkpointing saves you time (and money too)
That’s why the new checkpointing capability introduced in Cromwell 55 is so important: it allows you to save intermediate outputs for a given task, so if that task is preempted, when you relaunch, Cromwell will restart the job from that point in the analysis, potentially saving you hours of work. The new feature is described in full here.
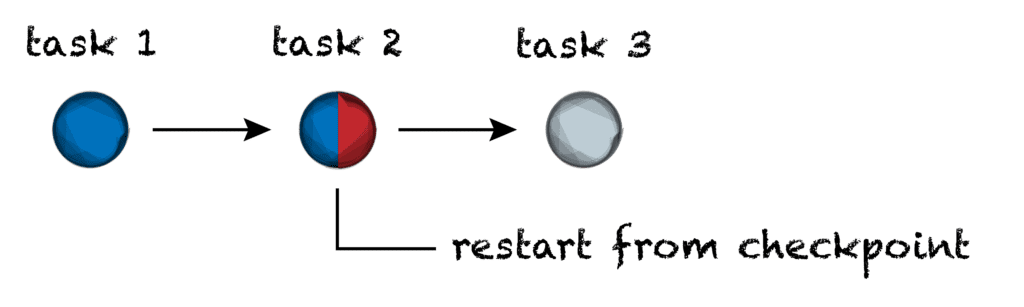
This does require that you write your WDL tasks with checkpointing in mind; you have to explicitly decide what information gets written to the checkpoint file, and how the contents of the checkpoint file should be used if the situation arises where the task is restarted. Not all tasks will be amenable to checkpointing. You can see a simple example of a checkpoint-enabled task in the Cromwell documentation. Other, more sophisticated usage examples will be provided in upcoming documentation.
Interestingly, this feature was originally prototyped as part of an internal hackathon by members of the GATK methods development team, who wanted a way to checkpoint machine learning model-building tasks that can run for many hours and are therefore more vulnerable to preemption. GATK team members hailed the checkpointing prototype as major optimization for dealing with preemptions on GCP in the germline copy number variant (gCNV) pipeline, which motivated the Cromwell team to implement the idea as a fully supported feature in the workflow engine. Now that checkpointing is available in Terra, GATK developers and our data engineering group are reviewing long-running steps in their pipelines for opportunities to take advantage of this “production-ready” implementation.
We hope this new feature will be useful to you as well; if you need help adapting your WDLs to use checkpointing, don’t hesitate to reach out to the Terra helpdesk.
