Terra’s workflow management system is designed to handle most of the computing infrastructure “busy work” on your behalf so that you can focus on your work rather than dealing with IT minutia. Sometimes that means we have to limit some options for practical reasons, yet we’re always looking for ways to increase your freedom to choose what’s right for you.
Most recently, we opened up a new option to allow you to use a newer model of Intel CPUs than what the system normally uses by default to execute workflow tasks. Until now, the system automatically assigned all workflow execution to a family of virtual machines (VMs) called “N1 instances”, which use CPUs from older generations of Intel processors. Now you’ll be able to request “N2 instances” instead, which use 2nd Generation Intel® Xeon® Scalable Processors, codenamed “Cascade Lake“. According to recent benchmarks, the Cascade Lake CPUs are capable of delivering substantial performance advantages at a lower cost for genomics workloads, so we’re excited to share the news that you can now opt into using them for your workflows in Terra.
Benchmarking results on GATK Best Practices workflows
Our colleagues in the GATK development team at the Broad Institute have a long-standing collaboration with an Intel team that focuses on optimizing genomics tools and pipelines, so they hooked us up with some benchmarking results that illustrate where the Cascade Lake CPUs make a big difference in the GATK Best Practices workflows.
Specifically, they compared the runtime and cost of all 24 tasks in the Broad Institute’s production implementation of the GATK Best Practices Pipeline for WGS Germline Variant Calling. Table 1 below provides a summary of the tasks in the pipeline, the number of VMs each task is distributed across, and the minimum number of CPUs, memory (DRAM), and disk required per VM for that task.
| Task | Number “shards,” or VMs | Min vCPU | Min DRAM (GB) | Min Local Disk (GB) |
| SortSampleBam | 1 | 1 | 4.9 | 379 |
| MarkDuplicates | 1 | 1 | 22.5 | 352 |
| ApplyBQSR | 19 | 1 | 3.4 | 253 |
| GatherBamFiles | 1 | 1 | 3.0 | 174 |
| HaplotypeCallerGATK4 | 50 | 2 | 6.5 | 114 |
| CheckContamination | 1 | 2 | 7.5 | 110 |
| BaseRecalibrator | 18 | 1 | 6.0 | 110 |
| CrossCheckFingerprints | 1 | 1 | 2.0 | 97 |
| CollectAggregationMetrics | 1 | 1 | 7.0 | 84 |
| CollectReadgroupBamQualityMetrics | 24 | 1 | 7.0 | 84 |
| CalculateReadGroupChecksum | 1 | 1 | 2.0 | 81 |
| ValidateVCF | 1 | 1 | 6.8 | 40 |
| SamToFastqAndBwaMemAndMba | 24 | 16 | 14.0 | 39 |
| CollectVariantCallingMetrics | 1 | 1 | 3.0 | 37 |
| MergeVCFs | 1 | 1 | 3.0 | 33 |
| CollectUnsortedReadgroupBamQuality Metrics | 24 | 1 | 7.0 | 25 |
| CollectQualityYieldMetrics | 1 | 1 | 3.0 | 23 |
| GatherBqsrReports | 1 | 1 | 3.4 | 20 |
| CreateSequenceGroupingTSV | 1 | 1 | 2.0 | |
| ScatterIntervalList | 1 | 1 | 2.0 | |
| GetBwaVersion | 1 | 1 | 1.0 | |
| SumFloats | 1 | 1 | ||
| Total | 181 |
They ran the workflow three times on N1 instances (N1-standard-2; N1-standard-16) and three times on N2 instances (N2-standard-2; N2-standard-16) on the Broad’s NA12878 30X coverage human whole genome sequence (WGS) test dataset.
Figure 1 below shows the median runtime for these two different instance types. As expected, the N2 instances with the later generation Intel Xeon Scalable processors have a faster runtime overall. The end-to-end pipeline executes in 24.9 hours compared to 32.9 hours when run on N1 instances.
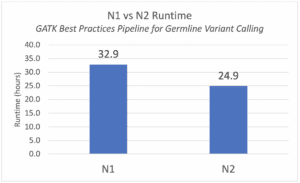
A closer look at per-task runtimes and cost (not shown here) tells us that the bulk of the speedup comes down to the two most compute-intensive tasks, SamToFastqAndBwaAndMba (genome mapping and formatting) and HaplotypeCaller (variant calling), which have the longest runtimes in the pipeline. This makes sense, since we know for example that the HaplotypeCaller task benefits from improved hardware accelerations on the latest Intel chips thanks to the use of the Intel Genomics Kernel Library, which includes accelerated implementations of the PairHMM and Smith-Waterman algorithms in HaplotypeCaller.
The overall cost of the pipeline is lower for N2 instances as well, with a median cost measured at $5 per WGS sample for the N2 instances vs $6 per WGS sample for the N1 instances (preemptible instances were used in both cases).
These results suggest that N2 instances are the more cost-effective and performant option compared to N1 instances. Opting to use N2 instances may be an attractive option for shaving off time and expense from your workflows, especially for the more compute-intensive tasks.
How to request N2 instances for your workflows
Terra’s workflow execution system, which uses the Cromwell workflow manager and the Workflow Description Language (WDL) under the hood, allows us to specify what kind of compute resources should be allocated for executing each step of our workflow.
For example, if we look at the WDL code for the HaplotypeCaller task mentioned in the benchmarking section above, the block of code that specifies the relevant runtime requirements looks like this:
runtime { docker: gatk_docker preemptible: preemptible_tries memory: "6.5 GiB" cpu: "2" bootDiskSizeGb: 15 disks: "local-disk " + disk_size + " HDD" }
This amounts to a request for a VM with 2 CPUs and at least 6.5 GB of memory, plus some additional characteristics we won’t cover in detail here. When you launch the workflow, Terra will translate these minimum requirements into a specific machine type request to the computing platform.
Where it gets a little complicated is that cloud vendors (here, Google Cloud) offer a lot of different machine types, further categorized into instance types such as N1 and N2 (there are multiple others), that are designed to satisfy a wide range of different computational needs. This introduces a lot of complexity into the question of how best to interpret the basic requirements encoded in the WDL workflow. For practical reasons, we reduce that complexity by having Terra use only a subset of instance types.
Specifically, on Google Cloud, Terra uses only N1 instances by default. The closest match to our example request in the list of N1 instances is the n1-standard-2 machine type, which has 2 CPUs and 7.5 GB of memory.
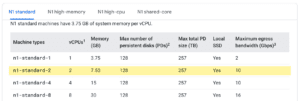
This means that when you launch the workflow, the system will create the VM(s) for running that HaplotypeCaller task based on the n1-standard-2 machine type.
However, as noted above you can now choose to use N2 instance types instead, which have similar technical profiles to the N1 instances but are equipped with the newer generation of Intel® Xeon® Scalable Processors, aka Cascade Lake CPUs.
The not-so-obvious trick here is that to request an N2 instance for a task, you’ll need to specify cpuPlatform: “Intel Cascade Lake” in the task’s runtime block. Going back to our earlier example, this is what the runtime block would look like for our HaplotypeCaller task in the WDL workflow:
runtime { docker: gatk_docker preemptible: preemptible_tries memory: "6.5 GiB" cpu: "2" cpuPlatform: "Intel Cascade Lake" bootDiskSizeGb: 15 disks: "local-disk " + disk_size + " HDD" }
That one line setting the cpuPlatform parameter is all it takes to make the switch.
Now Terra will request the closest match in the list of N2 instances: the n2-standard-2 machine type, which has 2 CPUs and 8 GB of memory.
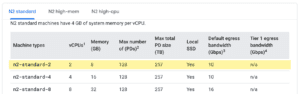
The cpuPlatform parameter refers to the processor family that is used in N2 instances, so this is a slightly indirect way of getting what we want… but whatever works, right?
The downside of being so specific about the cpuPlatform you want is that if there are no machines matching that requirement available at the time you make the request, your task will get queued until one becomes available. At times of peak utilization, that could end up delaying your workflow more than what you gain from using the upgraded hardware. We don’t have exact numbers on how many N2 instances are available relative to N1 instances in Google Cloud, and that proportion is likely to be zone-dependent, but it’s fair to guess that there are probably more N1 instances than N2 instances available at this time.
So for now, a conservative approach would be to use N2 instances for tasks where you know they make a big difference to cost and runtime (like the mapping and variant calling steps revealed by the GATK workflow benchmarks), and stick with N1 instances (ie not specify a cpuPlatform in task runtime blocks) for the rest. Over time we expect that the number of newer machines will increase and it will eventually make sense to switch over to N2 instances completely.
Acknowledgments
We are grateful to the Intel team, specifically Priyanka Sebastian, Keith Mannthey, and Marissa Powers, for running the GATK benchmarks and helping us characterize the benefits of using N2 instances.
Resources
Default runtime attributes for workflow submissions
Release notes announcing support for N2 instances
Cromwell documentation for the cpuPlatform parameter (introduced in version 64)
