Chase Thomas is a visiting Product Manager in the Data Sciences Platform at the Broad Institute. His goal is to support researchers using machine learning in Terra. In this guest blog post, Chase introduces a process called hyperparameter optimization that can help researchers improve their models, and presents a tutorial workspace that demonstrates how to use this process in practice.
Designing a machine learning model is hard. There is an overwhelming number of algorithms and parameters, and you often need intuition developed from experience to pick the right ones. In fact, even experienced practitioners find it difficult to know if they have found the optimal set of parameters for a given problem. Using traditional methods, it takes a lot of experimentation to manually select and tweak parameters, and gradually improve results over many iterations. The process can be time-consuming, expensive, and the consequences of choosing the wrong configuration can be severe.
The good news is that it’s possible to automate this process to some extent through a method called “hyperparameter optimization”. There are tools that you can set up to automatically try different values for your model parameters and select the ones that produce the best performance, which is much more efficient than manual experimentation. This method is often used by experienced practitioners to make final improvements to their model, but it can also be used by newcomers to make things easier from the beginning.
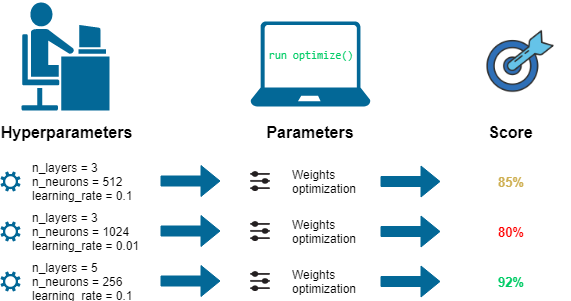
Hyperparameter optimization workflow (Figure by Dawid Kopczyk | via Pier Paolo Ippolito, Hyperparameters Optimization)
We wanted to make hyperparameter optimization more readily accessible to a wide range of users, so we put together a public Terra workspace with a tutorial that includes the necessary data and tools to apply hyperparameter optimization to an example dataset. Specifically, we used a toolkit called Optuna that is both powerful and easy to use, and that can be integrated with almost any mainstream machine learning package/framework. Using Optuna in a Jupyter Notebook, you can design an experiment, specify a range of values, then let the experiment run and determine the optimal model design.
Hyperparameter optimization in practice
To demonstrate this method, we put together a tutorial that walks you through developing a model to predict heart disease based on the Framingham Heart Study.
The Framingham Heart Study is a long-term, ongoing cardiovascular cohort study that began in 1948 with 5,209 adult subjects, and has since enrolled three additional generations of subjects totaling over 16,000 individuals. The dataset is a treasure trove for research, with detailed information on participant demographics, lifestyle factors, and medical history.
Over the past decades, researchers affiliated with the study developed statistical techniques to probe the relationship between these factors and disease risk, to help identify individuals who are at high risk for heart disease and who may benefit from lifestyle changes or medical intervention. Their research led to the development of the “Framingham risk score” (FRS) to predict risk of coronary heart disease.
Since then, recent papers have replicated and surpassed the performance of the Framingham Risk Score by using ML methods. We set out to build a predictive model in a similar way, but using hyperparameter optimization to minimize the amount of manual experimentation and effort involved.
The outcome? With just a few extra lines of code for Optuna, our approach designed a model that yielded competitive results in a fraction of the time that it would have taken to explore the parameter space manually.
For more details, check out the tutorial notebook in the public workspace, which shows how we set up Optuna to run trials and experiment with parameters in order to optimize the model. The tutorial walks you through all the steps, from importing data from Google BigQuery and cleaning it up (removing NaN values etc), to building and tuning different kinds of models (logistic regression, random forest and neural network), and finally, visualizing and interpreting results.
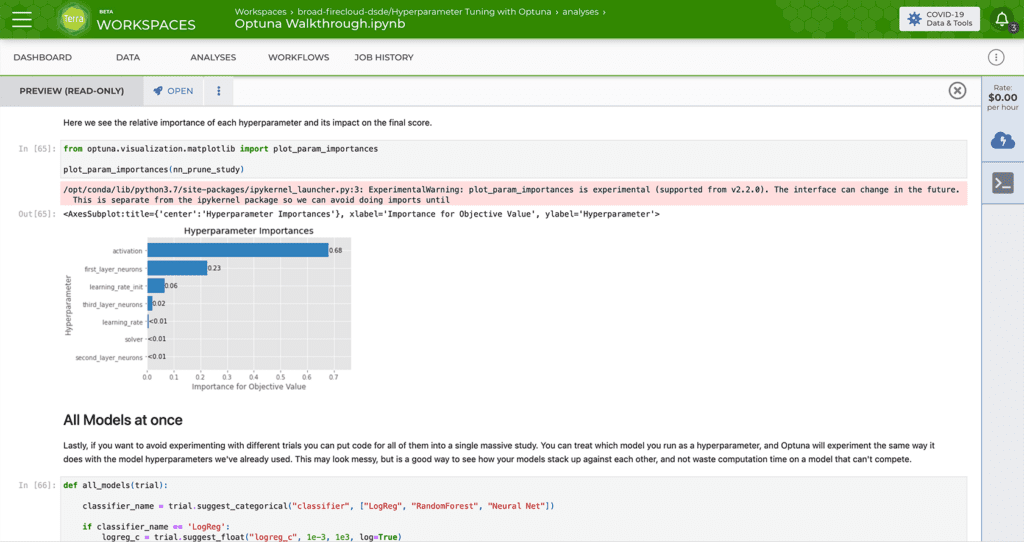
The bottom line: hyperparameter optimization can improve any prediction where a machine learning model is used. It can boost performance of a model you’ve already made, or help you design one from the beginning. Everything from diagnostic radiology to epidemiology to cancer genomics to single-cell transcriptomics can benefit. No matter your domain, we hope this tutorial will inspire you to try it out for yourself, in case hyperparameter optimization can save you time and improve the results of your next modeling project.
